Replicating 'It Takes Two Neurons To Ride a Bicycle'
I wanted to recreate this paper from 2004 at NeurIPS: “It Takes Two Neurons To Ride a Bicycle” from Matthew Cook. My complete implementation is available here.
Setting up the bike simulation
First, it turns out that it is actually hard to find the equations of motion that describe a bike. There is a plethora of papers ([1] [2] [3] [4], [5]) but in the end, it was much easier to just set this problem up in pybullet, and make a bike run in a full fledged simulator, compared to setting up some system of equations, and integrating that forward.
The bike I used was this one:

which is part of pybullet. But, the wheels have a wrong offset, resulting in the center of mass being offset to the side from the wheelbase. Thus, the coordinates of the visual and the inertial part of the ‘frontWheelLink’ and ‘backWheelLink’ in the urdf need to be changed to:
1
2
3
4
5
6
<collision>
<origin rpy="1.57 0 0" xyz="0 0.02762793 0"/>
<geometry>
<mesh filename="files/wheel_scaled.stl"/>
</geometry>
</collision>
After that was fixed, the bike behaves as expected, and does not constantly fall over to the right.
Path of an unsteered bicycle
My initial core motivation for reimplementing this paper was Figure 2 from the paper that shows the path of the frontwheel for 800 runs when the bike is not steered and pushed to the right. Here’s the original:

I was not able to get exactly the same result, but got pretty close. Here’s a few figures with different initial speeds (from the top left to the bottom right, 3m/s, 4m/s, 5m/s, 6m/s):
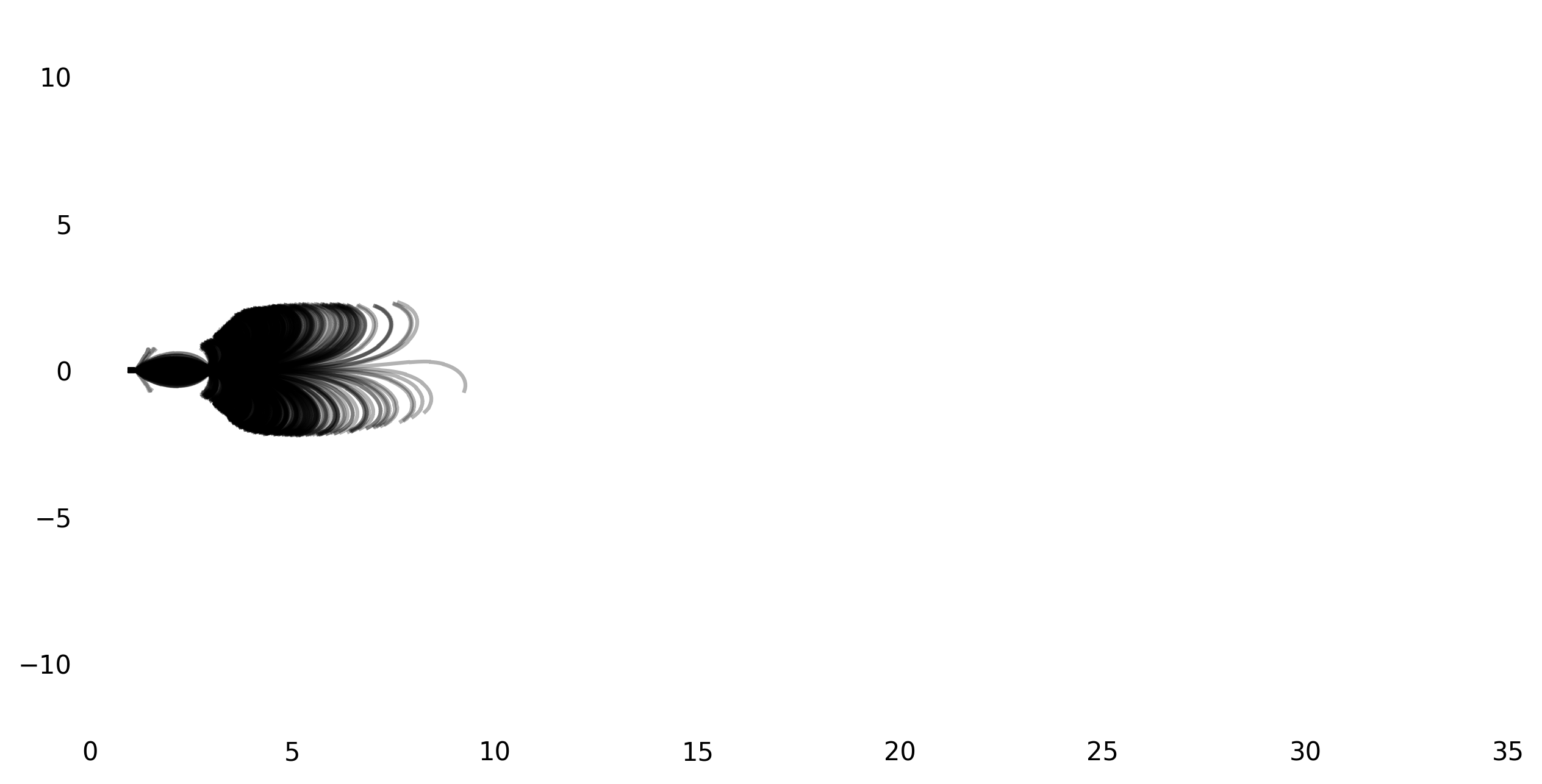
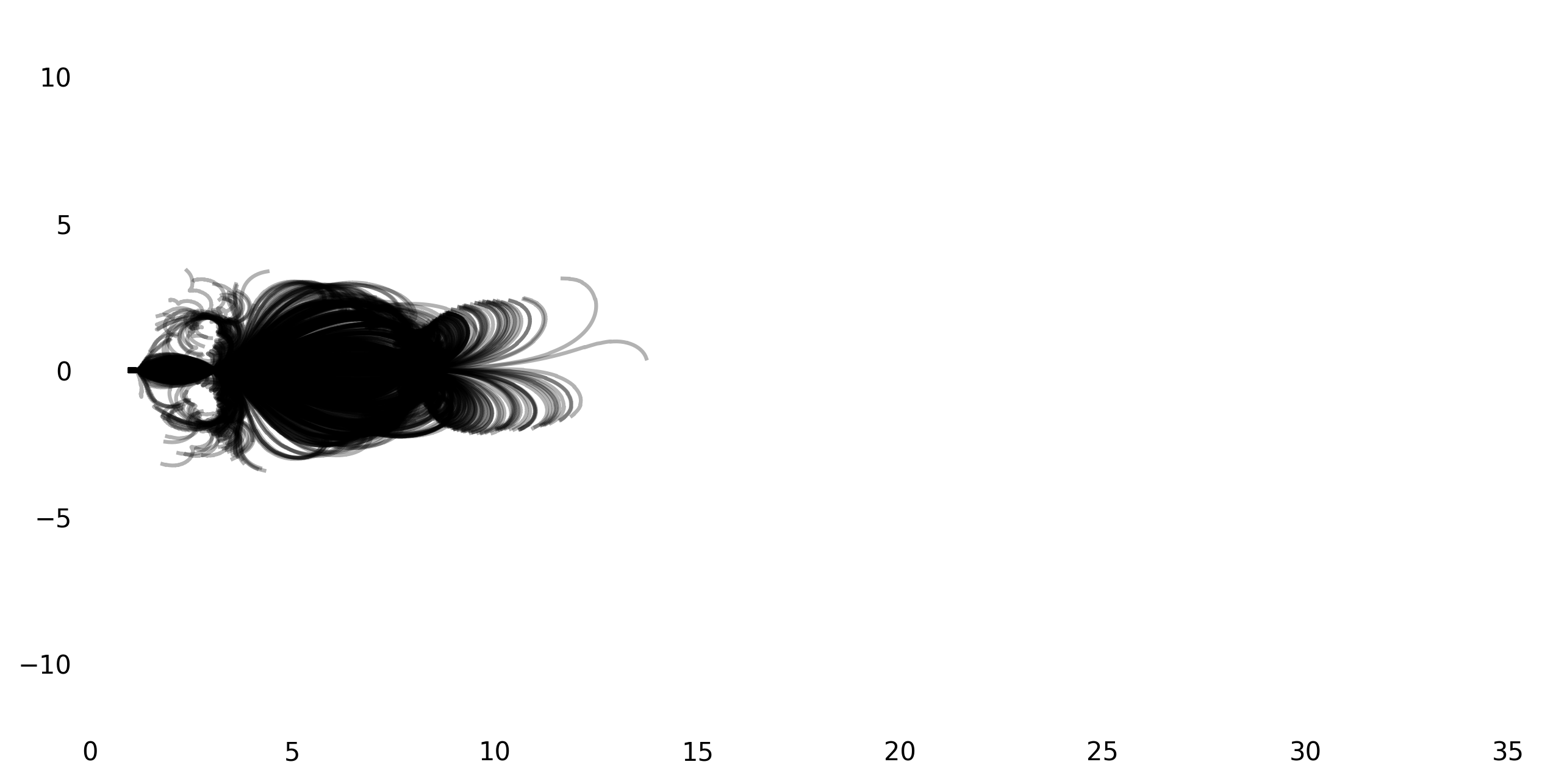
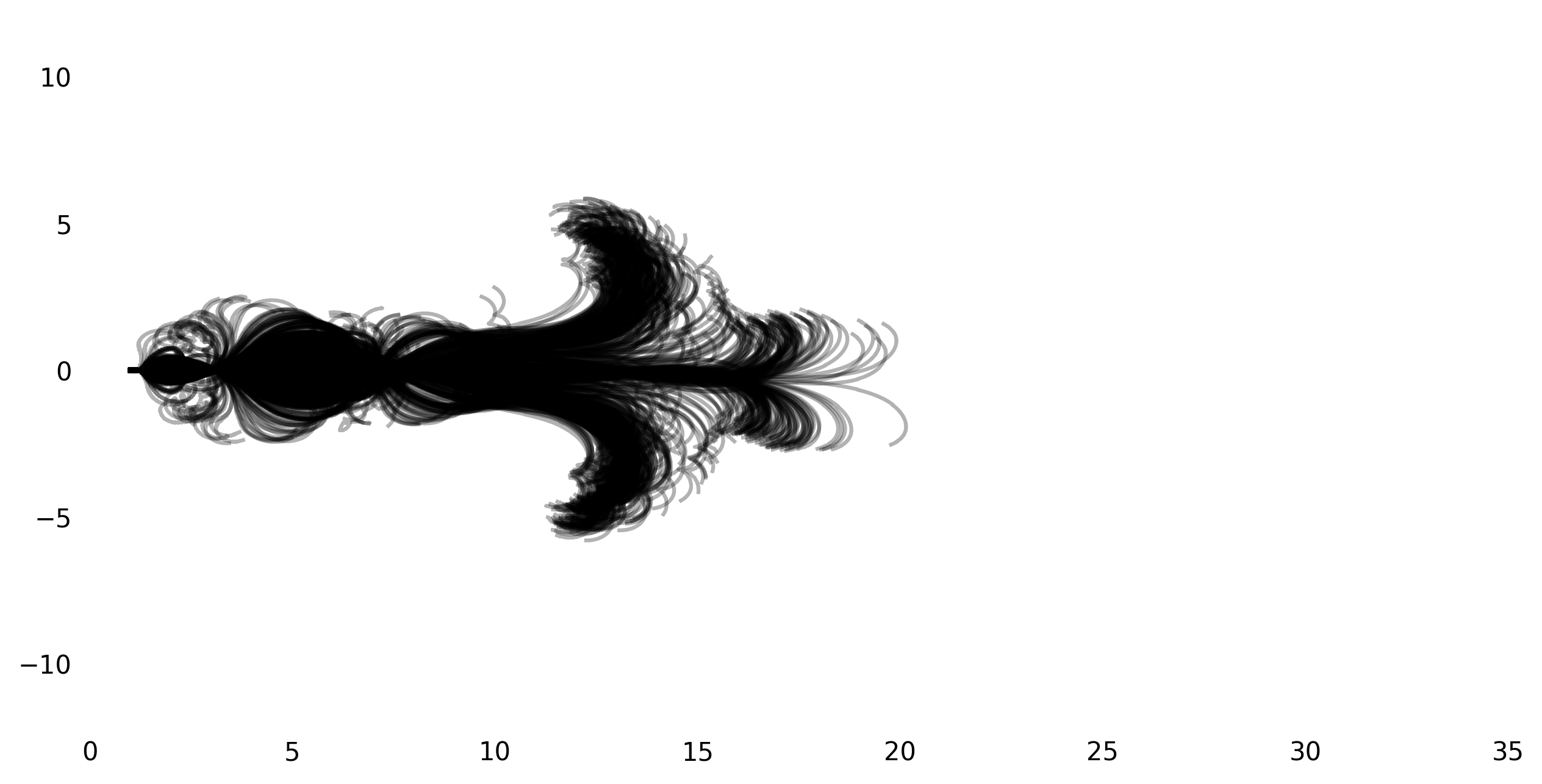
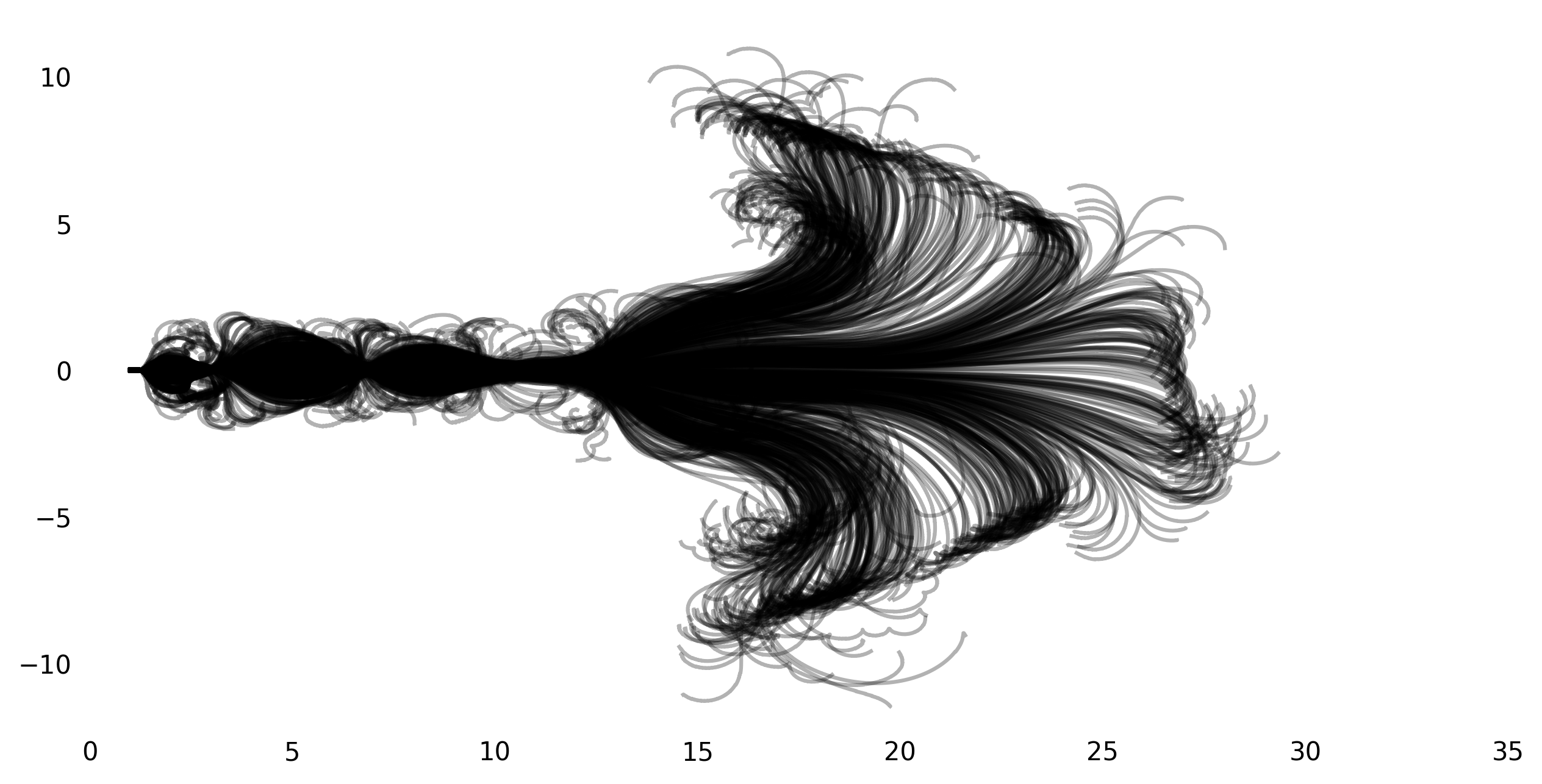
I suspect the main difference between the original plot and my reproductions is due to the different bike geometry. Generally, the result seems to be very sensitive to the initial conditions, so there is also the possibility that choosing the ‘right’ initial perturbations leads to an even more similar plot.
The two neuron controller and tracing a path
With the simulation up and running, I implemented the two-neuron-controller described by the paper.
The two neuron controller gets the heading of the bike \(\theta\), the leaning \(\gamma\), and the leaning-velocity \(\dot\gamma\) as inputThere appears to be a small error in the paper: It also talks of the output \(\phi\) of the second neuron being looped back into it, but the equations in the paper do not reflect that. . The action the controller takes is the torque that is applied to the handlebar.
The controller is then formed by the two equations:
\[\begin{align} \gamma_\text{desired} &= \sigma(c_1(\theta_\text{desired} - \theta))\\ \tau_h &= c_2(\gamma_\text{desired} - \gamma) - c_3\dot{\gamma} \end{align}\]Where \(\sigma()\) is a thresholding function that ensures that the controller does not go crazy if the desired angle is too far away from the actual angle. I used the sigmoid-function for \(\sigma\), and centered it around the x-axis. This is extremely close to a hierarchical PD controller of the form \(u = k_p * e + k_d * \dot{e}\).
There is one caveat here: The difference between two angles is not nicely described by subtracting the two angles from each other. This leads to issues if e.g. \(\theta_\text{desired}=-\pi+\varepsilon\) and \(\theta=\pi-\varepsilon\). The difference we want is \(2\varepsilon\), but the result we get when subtracting the two values is \(-2\pi+2\varepsilon\).
I did spend some time runing the parameters of this controller, resulting in the values \(c_1 = -1, c_2 = 100, c_3 = 100\) The controller is able to stabilize the bike and follow a path defined by a sequence of points. The points are used to compute the required angle, and once the bike gets close to a point, we are steering to the next point.
I spent some more effortThe effort was mostly spent on tuning the rewards. , and ran a random search to improve the controller parameters. I defined the reward \(R = -0.1 * (\theta - \theta_\text{desired}) + 1\) given at each timestep. This should punish deviation from a desired angle, but reward not falling over. Falling over lead to a ‘reward’ of \(-10000\). A reward of \(1000\) was given for reaching the next point in the path, and an additional reward of \(5000\) was given for reaching the last point in the path.
My hand-tuned, initial parameters reached \(27911.346\) on the reward above for a square path, and a circular path.
The best parameters of the random search were \(c_{1,2,3} = [-0.95, 22.959, 27.761 ]\), which reached a reward of \(44966.643\). This compareably higher reward is mainly due to the hand-tuned controller falling over in the square-path-following-task.
Looking back, I should have done the random search on some set of paths, and done the evaluation on some other paths (as essentially done in the hand-tuned controller, which was only tuned on the circle-path).
Following two paths looks like this for the hand tuned, and the found controller:
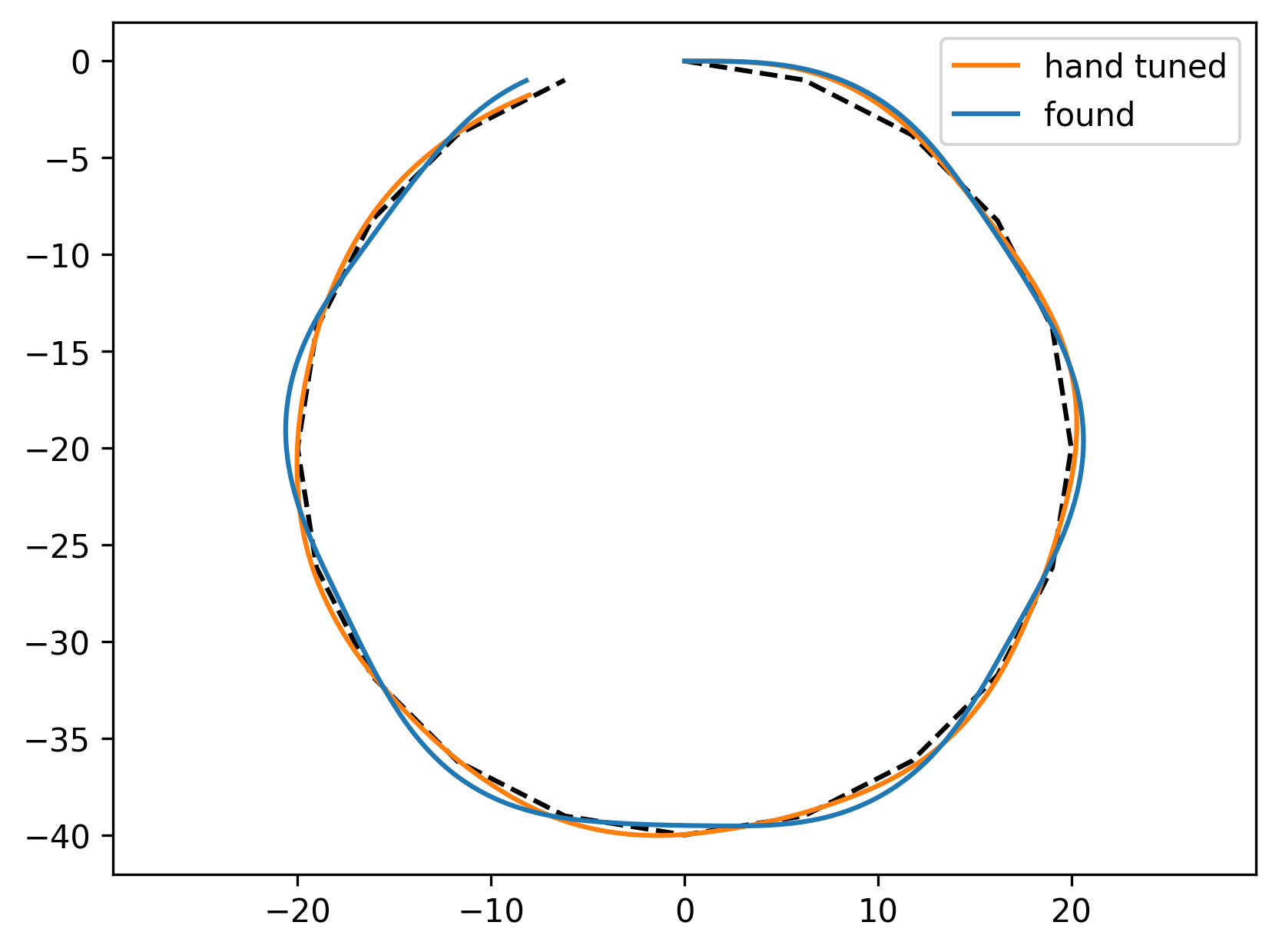
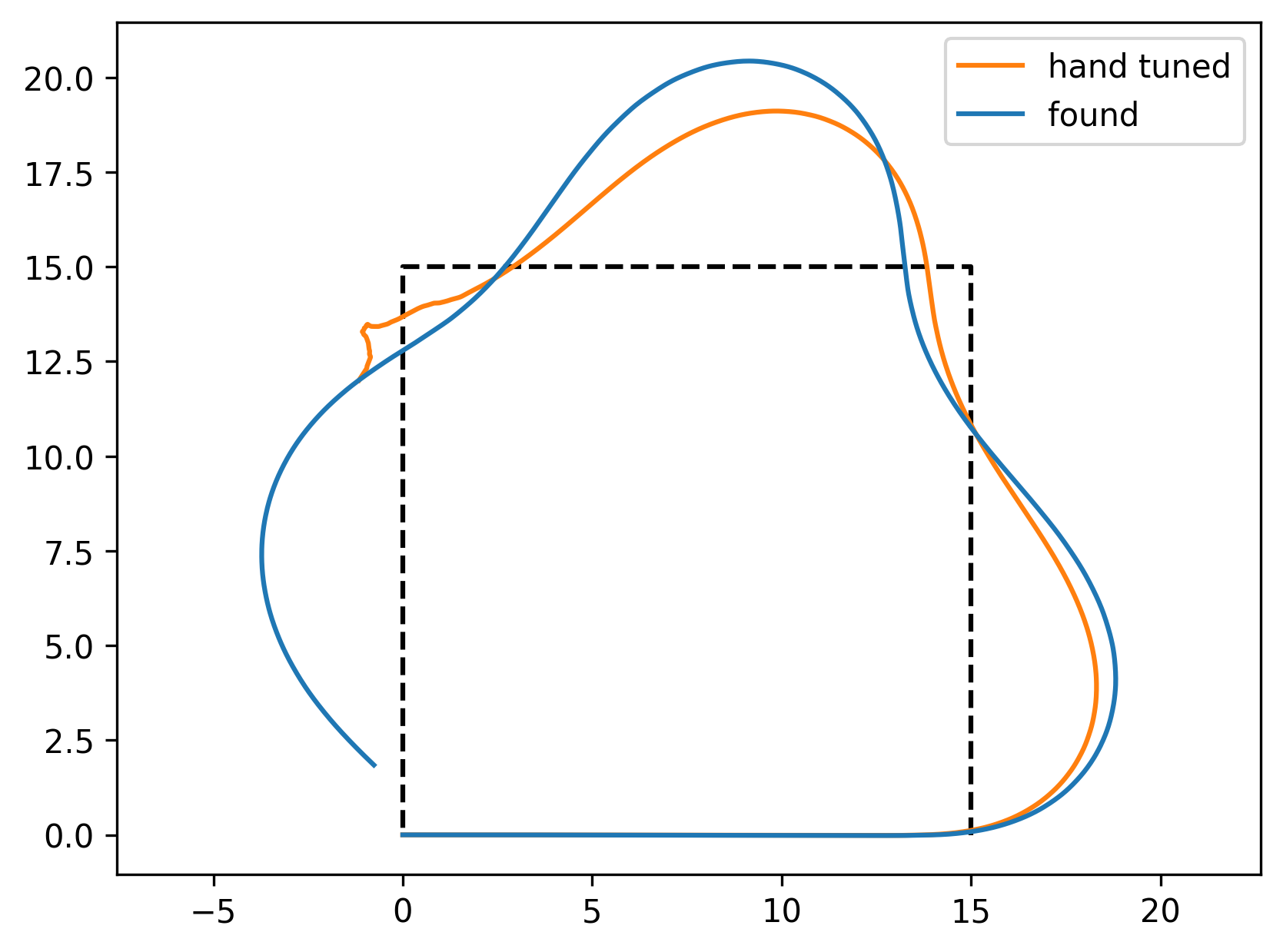
The paper also briefly discusses some RL controllers, but I’ll leave that to the future.
Final Words
The paper is fun, well written, and results in nice plots.
My main difficulty in replicating the paper were
- figuring out that the bike-model in pybullet has a center of mass that is offset, and
- computing the leaning and heading angles correctly.
I think the claim that two neurons are needed to ride a bike (given that it is actuated) is reasonable with the caveat that computation of the steering angle needs to be done carefully.
I might want to have a look at running some learning/control algorithm on this system, and also deal with pedalling speed to give the bike a bit more agility.